Table of Content:
- • 关于
- • 背景
- • 完整的生命周期
- • 达到的目标以及中间遇到的问题
- • 较低的接入成本,较高的定制能力
- • 语言开放性
- • 减少不稳定构建,降低问题复现成本
- • 缓存的设计
- • 依赖获取稳定性
- • 更低的排查错误的成本
- • 规范和标准的落地抓手
- • 高可用和可扩展的集群
- • Job 调度策略
- • 集群设计和故障恢复
- • 监控报警
- • 后续的计划
- • 参考资料
关于
知乎应用平台团队基于 Jenkins Pipeline 和 Docker 打造了一套持续集成系统。Jenkins Master 和 Slave 基于 Docker 部署,每次构建也是在容器中进行。目前有三千个 Jenkins Job,支撑着整个团队每日近万次的构建和部署量。
整个系统的设计目标是具备以下的能力:
- • 较低的应用接入成本,较高的定制能力:写一个构建系统配置文件成本要尽可能简单方便,或者可以通过模板一键创建,但又要能满足应用的各种定制化的需求。
- • 具备语言开放性和部署多样性:平台需要能支撑业务技术选型上的多语言,同时,要能满足应用不同的部署类型,如单纯的打包发布,或者进一步部署到物理机、容器、离线任务平台等。
- • 构建快和稳定,复现问题成本低:每次构建都在干净的容器中,减少非应用本身问题带来的构建异常。同时,如果构建出现问题,在权限控制的前提下,要能方便开发者自己调试和排查。
- • 推动业界标准以及最佳实践,同时在代码合并之前就能更好把控住质量。
- • 整个集群高可用,可扩展,以及具备较低的运维成本。
背景
知乎选用 Jenkins 作为构建方案,因其强大和灵活,且有非常丰富的插件可供使用和扩展。
早期,应用数量较少时,每个开发者都手动创建并维护着几个 Job,各自编写 Jenkins Job 的配置,以及手动触发构建。随着服务化以及业务类型,开发者以及 Jenkins Job 数量的增加,我们面临了以下的问题:
- • 每个开发者都需要去理解 Jenkins 的基本配置和触发逻辑,使得配置创建和维护成本高。
- • 构建在物理机上进行,每个应用可能有着不同的版本依赖,构建时会遇到版本冲突,甚至上线之后发现行为不一致导致故障等。
- • 构建一旦失败,需要开发者能登录 Jenkins Slave 所在的物理机进行调试,权限控制成为了一个问题
于是,一个能方便应用接入构建部署的系统,成为了必须。
完整的生命周期
知乎的构建工作流主要是以下两种场景:
- • 只有 Master 分支的代码可以用于线上部署,但支持指定任意的分支进行构建
- • 所有对 Master 分支的修改必须通过 Merge Request 来进行。为了避免潜在代码冲突导致测试结果不准的情况,对 Merge Request 上的代码进行构建前,会模拟跟 Master 分支的代码做一次合并。
一个 Commit 从提交到最后部署,会经历以下的环节:
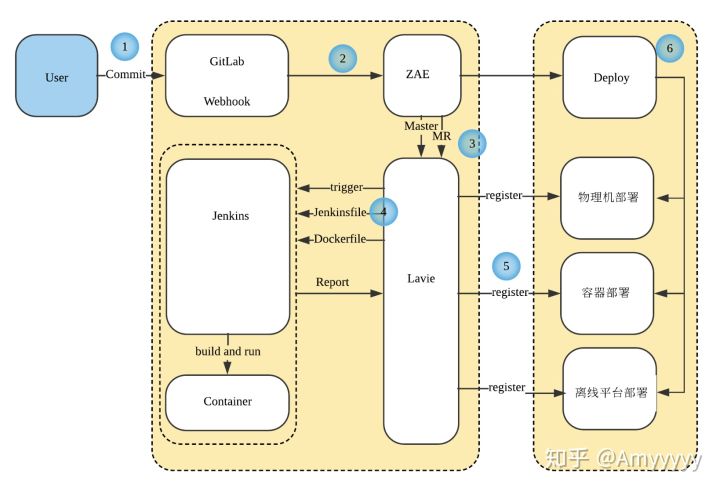
- 1开发者提交代码到 GitLab。
- 2GitLab 通过 Webhook 通知到 ZAE (Zhihu App Engine, 知乎的私有云平台)。
- 3ZAE 将构建的上下文信息,如 GitLab 仓库 ID,ZAE 应用信息给到构建系统 Lavie。目前只处理用户提交 MR 以及合并到 Master 分支的事件。
- 4构建系统 Lavie 读取应用仓库中的配置文件后生成配置,触发一个构建。在构建过程中获取动态生成的 Jenkinsfile,生成 Dockerfile 构建出应用的镜像,并跑起容器,在容器中执行构建,测试等应用指定的步骤。
- 5测试成功之后,分别往物理机部署平台,容器部署平台,离线任务平台上传 Artifact,注册待发布版本的信息,并 Slack 通知用户结果。
- 6构建结束,用户在 ZAE 上可以进行后续操作,如选择一个候选版本进行部署。
每个应用的拉取代码,准备数据库,处理测试覆盖率,发送消息,候选版本的注册等通用的部分,都会由构建系统统一处理,而接入构建系统的应用,只需要在代码仓库中包含一个约定格式的配置文件。
达到的目标以及中间遇到的问题
- 1较低的接入成本,较高的定制能力
构建系统去理解应用要做的事情靠的是约定格式的 yaml 配置文件,而我们希望这个配置文件能足够简单,声明上必要的部分,如环境、构建、测试步骤就能开始构建。
同时,也要有能力提供更多的定制功能让应用可以使用,如选择系统依赖和版本,缓存的路径,是否需要构建系统提供 MySQL 以及需要的 MySQL 版本等。以及可以根据应用的类别自动生成配置文件。
一个最简单的应用场景:
base_image: python2/jessie
build:
- buildout
test:
unittest:
- bin/test --cover-package=pin --with-xunit --with-coverage --cover-xml一个更多定制化的场景:
base_image: py_node/jessie
deps:
- libffi-dev
build:
- buildout
- cd admin && npm install && gulp
test:
deps:
- mysql:5.7
unittest:
- bin/test --cover-package=lived,liveweb --with-xunit --with-coverage
coverage_test:
report_fpath: coverage.xml
post_build:
scripts:
- /bin/bash scripts/release_sentry.sh
artifacts:
targets:
- docker
- tarball
cache:
directories:
- admin/static/components
- admin/node_modules为了尽可能满足多样化的业务场景,我们主要将配置文件分为三部分:声明环境和依赖、构建相关核心环节、声明 Artifact 类型。
声明环境和依赖
- •
image,基础镜像,需要指明已提前准备好的语言镜像 - •
deps,dependencies 的简写, 声明使用的系统依赖以及对应的版本
构建相关核心环节
- •
build,构建的步骤,如 buildout, npm install ,或者执行一个脚本 - •
test,测试环节,应用需要声明构建的步骤,也可以在这里定制使用的 MySQL 以及对应的版本。构建系统会每次为其创建新的数据库,将关键信息 export 为环境变量。 - •
post build,最后一个环节,如发包,发 Slack 、邮件通知,或发布一个 Sentry release 等
声明 Artifact 类型
artifact,用于选择部署的类型, 目前支持的有:
- •
tarball:构建系统会将整个应用 Workspace 打包上传到 HDFS 用于后续的物理机部署 - •
docker:镜像会被 push 到私有的 Docker Registry 用于容器部署 - •
static:应用指定的路径打包后会被上传到 HDFS,用于后续的静态资源部署 - •
offline: 应用指定的文件会被上传到离线平台,用于离线任务的执行
2. 语言开放性
早期所有的构建都在物理机上进行,构建之前需要提前在物理机上安装好对应的系统依赖,而如果遇到所需要的版本不同时,调度和维护的成本就高了很多。随着团队业务数量和种类的增加,技术选型的演进,这样的挑战越来越大。于是构建系统整体的优化方向由物理机向 Docker 容器化前进,如今,所有构建都容器中进行,基础的语言镜像由应用自己选择。
目前镜像管理的方式是:
- • 我们会事先准备好系统的基础镜像
- • 在系统镜像的基础上,会构建出不同的语言镜像供应用使用,如 Python,Golang,Java,Node,Rust 的各种版本以及混合语言的镜像。
- • 在应用指定的
image语言镜像之上,会安装上deps指定的系统依赖,再构建出应用的镜像,应用会在这个环境里面进行构建测试等。
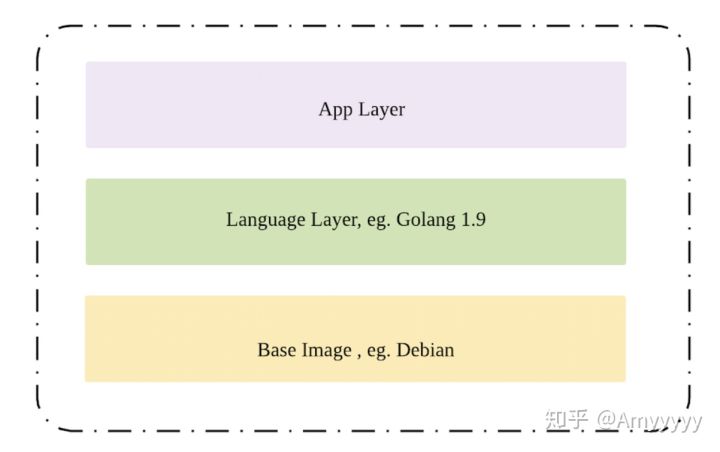
语言这一层的 Dockerfile 会被严格 review,通过的镜像才能被使用,以更好了解和支持业务技术选型和使用场景。
3. 减少不稳定构建,降低问题复现成本
缓存的设计
最开始构建的缓存是落在对应的 Jenkins Slave 上的,随着 Slave 数量的增多,应用构建被分配到不同 Slave 带来的代价也越来越大。
为了让 Slave 的管理更加灵活以及构建速度和 Slave 无关,我们最后将缓存按照应用使用的镜像和系统依赖作为缓存的标识,上传到 HDFS。在每次构建前拉取,构建之后再上传更新。
针对镜像涉及到的语言,我们会对常见的依赖进行缓存,如 eggs, node_modules, .ivy2/cache, .ivy2/repository。应用如果有其他的文件想要缓存,也支持在配置文件中指定。
依赖获取稳定性
在对整个构建时间的开销和不稳定因素的观察中,我们发现拉取外部依赖是个非常耗时且失败率较高的环节。
为了让这个过程更加稳定,我们做了以下的事情:
- • 完善内部不同语言的源
- • 在不同语言的基础镜像中放入优先使用内部源的配置
- • 搭建 HTTP Proxy,提供给以上覆盖不到的场景
更低的排查错误的成本
本地开发和构建环境存在明显的差异,可能会出现本地构建成功但是在构建系统失败的情况。
为了让用户能够快速重现,我们在项目 docker-ssh 的基础上做了二次开发,支持直接 ssh 到容器进行调试。由于容器环境与其他人的构建相隔离,我们不必担心 ssh 权限导致的各种安全问题。构建失败的容器会多保留一天,之后便被回收。
4. 规范和标准的落地抓手
我们希望能给接入到构建系统的提高效率的同时,也希望能推动一些标准或者好的实践,比如完善测试。
围绕着测试和测试覆盖率,我们做了以下的事情:
- • 配置文件中强制要有测试环节。
- • 应用测试结束之后,取到代码覆盖率的报告并打点。在提交的 Merge Request 评论中会给出现在的值和主分支的值的比较,以及最近主分支代码覆盖率的变化趋势。
- • 在知乎有应用重要性的分级,对于重要的应用,构建系统会对其要求有测试覆盖率报告,以及更高的测试覆盖率。

对于团队内或者业界的基础库,如果发现有更稳定版本或者发现有严重问题,构建系统会按照应用的重要性,从低到高提示应用去升级或者去掉对应依赖。

5. 高可用和可扩展的集群
Job 调度策略
Jenkins Master 只进行任务的调度,而实际执行是在不同的 Jenkins Node 上。
每个 Node 会被赋予一些 label 用于任务调度,比如:mysql:5.6, mysql:5.7, common 等。构建系统会根据应用的类型分配到不同的 label,由 Jenkins Master 去进一步调度任务到对应的 Node 上。
高可用设计
集群的设计如下,一个 Node 对应的是一台物理机,上面跑了 Jenkins Slave (分别连 Master 和 Master Standby),Docker Deamon 和 MySQL(为应用提供测试的 MySQL)。
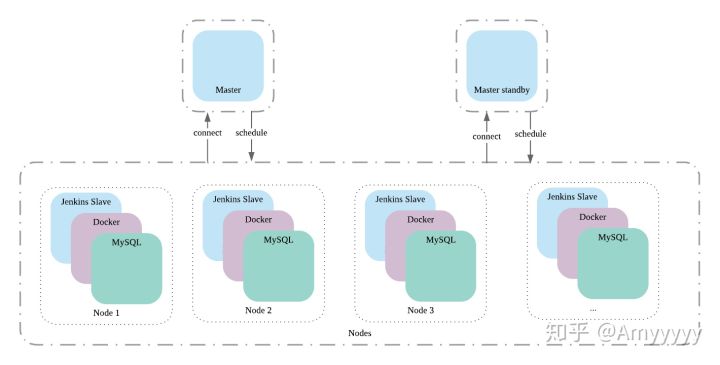
Slave 连接 Master 等待被调度,而当 Jenkins Slave 出现故障时,只需摘掉这台 Slave 的 label,后续将不会有任务调度调度上来。
而当 Jenkins Master 故障时,如果不能短时间启动起来时,集群可能就处于不可用状态了,从而影响整个构建部署。为了减少这种情况带来的不可用,我们采用了双 Master 模型,一台作为 Standby,如果其中一台出现异常就切换到另一台健康的 Master。
监控和报警
为了更好监控集群的运行状态,及时发现集群故障,我们加了一系列的监控报警,如:
- • 两个 Jenkins Master 是否可用,当前的排队数量情况。
- • 集群里面所有 Jenkins Node 的在线状态,Node 被命中的情况。
- • Jenkins Job 的执行时间,是否有不合理的过长构建或者卡住。
- • 以及集群机器的 CPU,内存,磁盘使用情况。
后续的计划
在未来我们还希望完善以下的方面:
- • Jenkins Slave 能更根据集群的负载情况进行动态扩容。
- • 一个节点故障时能自动下掉并重新分配已经在上面执行的任务。一个 Master down 掉能被主动探测到并发生切换。
- • 在 Merge Request 的构建环节推动更多的质量保证标准实施,如更多的接口自动化测试,减少有问题的代码被合并到主分支。
主要开发者(排名不分先后):
参考资料
- • Jenkinsfile 相关文档 https://jenkins.io/doc/book/pipeline/jenkinsfile/...
- • Jenkins Logo: https://jenkins.io/
- • Docker Logo: Brand Guidelines